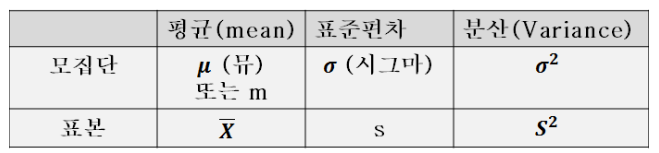
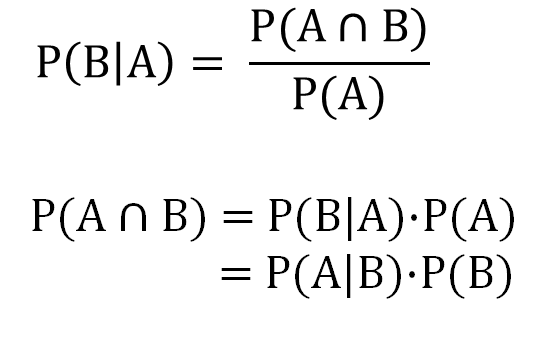임상 Database에는 다양한 종류의 DB가 사용된다. Somatic과 관련된 DB로는 대표적으로 OncoKB, Civic, Clinvar 등이 있으며 오늘 소개할 DB는 CKB( ClinicalKnowledgebase) 이다. CKB란? clinical desicion making을 하기 위해 암환자의 서열정보와 관련된 inhouse-databse 이다. Precision medicine은 개인의 유전체, 환경 및 생활 양식을 고려하여 질병의 예방과 치료를 맞춤화하는 의학적 접근 방식을 가리킵니다. 이는 각 개인의 유전적, 생물학적, 생화학적 특성을 고려하여 질병의 원인을 이해하고, 이에 맞는 치료 및 예방 전략을 개발하는 것을 목표로 한다. 특히 암에서의 precision medicine에서는 암종..